Java od środka, czyli jak to wszystko działa?

Podczas naszych wyzwań dowiedzieliśmy się, że nasze programy pisane w języku Java działają dzięki wirtualnej maszynie Java. Dowiedzieliśmy się także, że na wirtualnej maszynie Java można uruchamiać programy napisane w innych językach programowania jak np. Scala, Groovy czy Kotlin. Dzisiejszy post będzie poświęcony temu, jak to wszystko działa. Nie jest to wiedza niezbędna, by zacząć swoją przygodę z programowaniem, wręcz przeciwnie, wielu programistów potrafi polec na rozmowie kwalifikacyjnej o pytania dotyczące maszyny wirtualnej, jednak do biegłego posługiwania się językami ze świata maszyny wirtualnej Java, warto dowiedzieć się co mamy pod przysłowiową maską.
Maszyna wirtualna Java
Wszystko zaczyna się od Wirtualnej Maszyny Java. To ona stoi za wielkim sukcesem całej platformy Java. To także ona jako pierwsza musi być zainstalowana w naszym komputerze by móc uruchomić jakiekolwiek aplikacje napisane w języku Java.
W praktyce JVM jest to jakiś program instalowany tak jak inne programy w naszym komputerze. Oznacza to, że wirtualna maszyna pracuje w danym systemie operacyjnym i musi być z nim zgodna, stąd na stronie Oracle można ją ściągnąć dla takich systemów jak Windows, Linux, macOS czy Solaris. Także Android (Dalvik) i inne systemy mobilne lub wbudowane mają swoją wersję maszyny wirtualnej. Możemy nawet uruchamiać programy w Javie na Lego Mindstorms.
Jest także wiele implementacji JVM. Najpopularniejsza jest oczywiście wirtualna maszyna tworzona przez firmę Oracle, zaś wcześniej przez firmę Sun, tak zwana Oracle HotSpot. Firma Oracle przejęła też projekt innej maszyny wirtualnej produkowanej przez BEA Systems, czyli JRockit. Projekt ten został jednak zamknięty, zaś część jego kodu została przeniesiona do maszyny wirtualnej Oracle oraz do projektu OpenJDK. Jest to otwarto źródłowa implementacja maszyny wirtualnej zainicjowana jeszcze przez firmę Sun. Jest to domyślna implementacja stosowana w systemach Linux oraz obrazach Docker’a czy innych systemów konteneryzacji. Projekt OpenJDK jest także prowadzony przez firmę Oracle przy współpracy z innymi firmami i programistami z całego świata. Tak naprawdę, obecna wersja maszyny wirtualnej Java dostępnej na stronie jest hybrydą dwóch starszych wersji przejętych przez firmę Oracle (HotSpot i JRockit) oraz w dużej mierze bazuje na OpenJDK. Plan firmy Oracle, zapowiedziany na filmie, jest taki, by OpenJDK była wersją krótkoterminową, przeznaczoną dla zwykłych użytkowników, developerów, zaś Oracle JDK ma być wersję długoterminową, dla firm i instytucji, którym zależy na stabilności przed długi czas oraz ma zawierać dodatkowe, komercyjne funkcjonalności. Zmienił się także sposób wprowadzania nowych zmian, od wersji 9tej, nowa wersja maszyny wirtualnej i języka Java ma być wydawana co pół roku, zaś co 3 lata ma być wydawana wersja LTS czyli Long Term Support, przeznaczona właśnie dla firm wymagających dłuższego utrzymania.
Na rynku dostępnych jest także sporo implementacji innych firm. IBM oraz fundacja Eclipse stoi za rozwojem maszyny wirtualnej IBM J9. Firma Azul System rozwija swoją otwarto źródłową wersję maszyny wirtualnej Zulu opartej o OpenJDK oraz komercyjną wersję Zing.
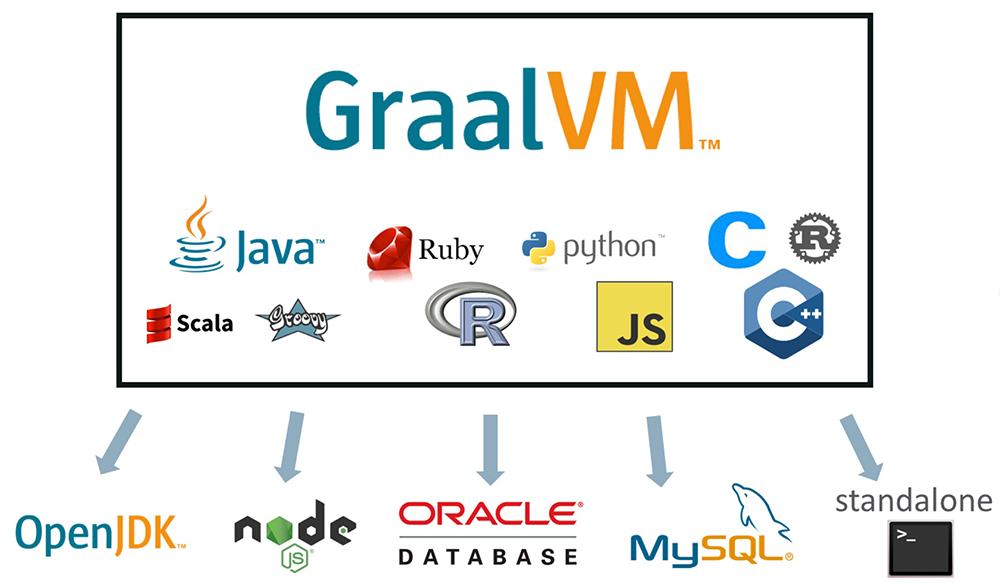
Jedną z nowości w świecie Java są prace nad nową wersją maszyny wirtualnej zwanej GraalVM. Celem projektu jest stworzenie jeszcze wydajniejszej wersji JVM wspierającej więcej języków programowania, jak JavaScript (także Node.js), C, C++, Rust, Ruby, R czy Python. GrallVM ma się stać także częścią baz danych MySQL oraz Oracle. W przeciwieństwie do innych maszyn wirtualnych, GraalVM jest napisany głównie w języku Java (97.3%).
Więcej innych implementacji wirtualnej maszyny możecie znaleźć na tej oraz tej stronie Wikipedii.
Każda licząca się maszyna wirtualna musi spełniać specyfikację oraz przejść Java Technology Compatibility Kit, TCK.
Wirtualna maszyna Java jest udostępniana w dwóch wersjach, Java Runtime Environment (JRE) zawierająca podstawową instalację maszyny wirtualnej wraz z dodatkowymi bibliotekami i komponentami, służącą przede wszystkim do uruchamiania programów oraz Java Development Kit (JDK) zawierająca wszystko co ma JRE plus dodatkowe narzędzia dla programistów. Poniżej diagram przedstawiający różnice między obydwiema wersjami dostępny na stronie Oracle.
Od kodu do programu, czyli proces kompilacji
Java jest językiem kompilowanym, to znaczy, że zanim uruchomimy nasz program, cały nasz kod będzie musiał zostać poddany procesowi kompilacji do postaci zrozumiałej dla komputera. W przypadku Javy, nasze programy będą uruchamiane przez maszynę wirtualną Java, więc narzędzie zwane kompilatorem będzie tłumaczyć nasz kod Java do postaci kodu maszynowego zrozumiałego dla JVM. Dlatego bez względu na to, jakiego języka programowania użyjemy, Java, Scala, Kotlin, Groovy, etc, nasz kod zawsze będzie tłumaczony do kodu maszyny wirtualnej, zwanego bytecode. Dopiero sama maszyna wirtualna tłumaczy ten kod dalej do postaci zrozumiałej przez system operacyjny naszego komputera.
Jako programiści będziemy pisać nasz kod Java w plikach .java, zaś kompilator będzie je tłumaczył na bytecode i umieszczał w plikach .class. W przypadku środowiska IntelliJ IDEA, pliki typu class znajdują się domyślnie w katalogu out. Po kliknięciu takiego pliku .class w środowisku IntelliJ IDEA, możemy zobaczyć kod w języku Java. Dzieje się tak dzięki dekompilacji, czyli procesowi odwrotnemu do kompilacji, polegającemu właśnie na uzyskaniu kodu źródłowego z plików .class. Oczywiście nie będzie to dokładnie nasz kod, tylko wygenerowany kod Java pasujący do zawartości pliku .class.
Kompilator jest dla programistów bardzo przydatnym narzędziem. Już na etapie tłumaczenia naszego kodu na język maszyny wirtualnej jest w stanie wyłapać wszystkie błędy składni (dostajemy wtedy tak zwany błąd kompilacji) oraz ostrzega nas przed wieloma potencjalnymi błędami. Drugą zaletą języków kompilowanych jest możliwość “zrzucenia” części własnej pracy na kompilator, który może za nas wykonać część pracy, by skrócić nasz czas. Jednym z przykładów jest tutaj choćby słowo var, gdzie to kompilator domyśla się typu zmiennej.
Środowiska programistyczne proces kompilacji wykonują za nas. W praktyce, do budowania większych projektów używa się odpowiednich narzędzi jak Maven czy Gradle (wcześniej popularny był Ant), które także wykonują tą pracę za nas. Jednak nic nie stoi na przeszkodzie byśmy sami skompilowali nasz kod. Wraz z JDK dostajemy narzędzie javac, które jest właśnie kompilatorem języka Java. Co ciekawe, jest ono także stworzone w oparciu o język Java.
Załóżmy że mamy taką klasę Java:
package pl.kodolamacz.myclasses;
public class Person {
public String forename;
public String surname;
public int age;
public Person() {
}
public Person(String forename, String surname, int age) {
this.forename = forename;
this.surname = surname;
this.age = age;
}
public void introduceYourself() {
System.out.println("Nazywam się " + forename + " " + surname + ". Mam " + age + " lat.");
}
public int growOld(int age) {
this.age += age;
return this.age;
}
}
Znajduje się ona w pliku Person.java. Żeby ją skompilować wystarczy w konsoli wpisać:
javac Person.java
Po wykonaniu powyższego polecenia, w tym samym katalogu powstanie plik Person.class. Zawartość nowo otrzymanego pliku nie jest zbyt czytelna dla człowieka, ale gdybyśmy chcieli zajrzeć do środka możemy użyć programu javap, który pozwala nam na rozłożenie pliku *.class na czynniki pierwsze (ang. disassemble). Domyślnie program javap wykonany bez żadnych parametrów pokazuje nam pakiet, pola public i protected oraz metody:
$ javap Person.class
Compiled from "Person.java"
public class pl.kodolamacz.myclasses.Person {
public java.lang.String forename;
public java.lang.String surname;
public int age;
public pl.kodolamacz.myclasses.Person();
public pl.kodolamacz.myclasses.Person(java.lang.String, java.lang.String, int);
public void introduceYourself();
public int growOld(int);
}
Jednak gdy dodamy flagę -c, wtedy program wyświetli nam instrukcje kodu maszynowego Java (bytecode) zgodnie ze specyfikacją języka:
$ javap -c Person.class
Compiled from "Person.java"
public class pl.kodolamacz.myclasses.Person {
public java.lang.String forename;
public java.lang.String surname;
public int age;
public pl.kodolamacz.myclasses.Person();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public pl.kodolamacz.myclasses.Person(java.lang.String, java.lang.String, int);
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: aload_1
6: putfield #2 // Field forename:Ljava/lang/String;
9: aload_0
10: aload_2
11: putfield #3 // Field surname:Ljava/lang/String;
14: aload_0
15: iload_3
16: putfield #4 // Field age:I
19: return
public void introduceYourself();
Code:
0: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: getfield #2 // Field forename:Ljava/lang/String;
7: aload_0
8: getfield #3 // Field surname:Ljava/lang/String;
11: aload_0
12: getfield #4 // Field age:I
15: invokedynamic #6, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;I)Ljava/lang/String;
20: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
23: return
public int growOld(int);
Code:
0: aload_0
1: dup
2: getfield #4 // Field age:I
5: iload_1
6: iadd
7: putfield #4 // Field age:I
10: aload_0
11: getfield #4 // Field age:I
14: ireturn
}
Gotowy program
W przeciwieństwie do programów napisanych np. w języku C++, gotowe programy, czyli zbiór plików *.class, nie są umieszczane w pliku exe, lecz są pakowane do plików .jar. Plik jar to tak naprawdę plik typu zip, dlatego bez problemu możemy go otworzyć i zobaczyć co jest w środku oraz dzięki kompresji ma on mniejszy rozmiar. Oprócz plików *.class., we wnętrzu pliku jar mogą znajdować się dodatkowe pliki potrzebne do wykonania programu.
W środowisku IntelliJ IDEA, by zbudować plik jar ze swojego projektu, należy wejść do ustawień projektu (Plik -> Project Structure). W nowo otwartym oknie należy kliknąć zakładkę “Artifacts” z lewej strony, a następnie nacisnąć zielony przycisk “plus”. Z listy wybieramy opcję “JAR”, a następnie “From modules with dependencies”. W kolejnym okienku wskazujemy klasę z metodą main, którą chcemy uruchomić, naciskamy “OK” i zamykamy wszystkie okna ponownie naciskając “OK”. Gdy już mamy stworzony artefakt definiujący nasz plik jar, wystarczy go zbudować klikając “Build -> Build Artifacts”, a następnie wybierając nazwę naszego artefaktu i klikając znowu “Build”. Nasz plik pojawi się w katalogu “out/artifacts/**”.
Plik jar możemy uruchomić używając polecenia java:
java -jar my-jar.jar
Informacja o klasie, w której uruchamiana jest metoda main, znajduje się w pliku MANIFEST.MF:
Manifest-Version: 1.0
Main-Class: pl.kodolamacz.MyApplication
Jak to działa?
Jednak co się dzieje, gdy próbujemy uruchomić nasz plik jar? W pierwszej kolejności, uruchamiana jest maszyna wirtualna Java. Pierwszą rzeczą którą robi to załadowanie klas, czyli wczytanie plików .class znajdujących się w pliku jar. Odpowiada za to narzędzie zwane ClassLoader. Po wczytaniu następuje proces łączenia (Linking), który dzieli się na pięć etapów. Najpierw następuje weryfikacja (Verification) poprawności klas, potem faza przygotowania (Preparation) gdzie następuje stworzenie pól statycznych oraz ich inicjalizacja wartościami domyślnymi, a następnie etap rozwiązania (Resolution) zależności pomiędzy klasami, czyli upewnienia się, że wszystkie typy z których chcemy skorzystać są dostępne oraz czy mają oczekiwane pola i metody. To w ostatnim etapie możemy dostać takie błędy jak NoSuchFieldError, NoSuchMethodError, IllegalAccessError znane dobrze programistom Java. Gdy wszystko zostanie prawidłowo rozwiązane, następuje faza sprawdzenia dostępów do pól, metod i klas (Access Control), czyli uwzględnienie takich słów jak public, protected, private, a na koniec faza zastępowania nadpisanych metod (Overriding). Gdy już przeszliśmy przez proces łączenia (Linking), następuje faza inicjalizacji klas, po której są one już gotowe do użycia. Jeśli korzystamy z metod natywnych, np. napisanych w języku C++, są one ładowane po inicjalizacji klas. Teraz następuje wykonanie naszego programu. Gdy program zamyka się, wywoływana jest metoda System.exit(status), która znowu wywołuje Runtime.getRuntime().exit(status). Wtedy następuje zatrzymanie maszyny wirtualnej i zwolnienie wszystkich zasobów.
Proces ten w całości opisany jest w specyfikacji maszyny wirtualnej w rozdziale piątym.
Optymalizacja
W trakcie działania maszyny wirtualnej, nasz kod, dokładnie bytecode, jest tłumaczony na kod maszynowy i wykonywany. Na pierwszy rzut oka może się wydawać, że ten proces dodatkowego tłumaczenia jest zbyt dużym kosztem działania programu, przez co powstało wiele legend mówiących o tym, że Java czy ogólnie środowisko JVM jest wolne. Oczywiście nie jest to prawdą, bo maszyny wirtualne zawierają w sobie szereg optymalizacji stosowanych w trakcie wykonywania programu, przez co potrafią uruchamiać operacje prawie tak szybko jak natywny kod napisany w języku C/C++ czy nawet niekiedy szybciej. Dzieje się to dzięki dynamicznemu kompilatorowi JIT czyli Just-In-Time. Jego zadaniem jest właśnie tłumaczenie kodu maszyny wirtualnej (bytecode) do kodu maszynowego wykonywanego na danym urządzeniu. W swojej pracy uwzględnia on zarówno to jak program działa, jak i architekturę sprzętową na którym działa program. Dlatego potrafi on jednocześnie przyśpieszyć często używane fragmenty kodu (tak zwane gorące punkty) jak i zoptymalizować kod wynikowy z uwzględnieniem używanego typu procesora. To właśnie uwzględnianie danego sprzętu oraz to jak program pracuje może spowodawać, że stworzony przez JIT kod maszynowy może być tak wydajny. Oczywiście może się okazać, że próby optymalizacyjne zastosowane przez JIT nie przyniosły oczekiwanego skutku, lecz wręcz przeciwny, więc kompilator może się wycofać ze swoich zmian i inaczej skompilować kod wynikowy. Takie próby skutkują tym, że maszyna wirtualna, do osiagnięcia swojej pełnej wydajności, potrzebuje się “rozgrzać”. Dlatego największy zysk ze stosowania JIT uzyskamy dla programów działających przez dłuższy czas, stąd bardzo często Java jest stosowana w rozwiazaniach serwerowych.
Jeżeli jeszcze tego nie zrobiliście, koniecznie dołączcie do naszego programistycznego wyzwania na Facebooku, nadróbcie zaległe wyzwania i kontynuujcie wspólnie z nami przygodę z Javą.



