Wprowadzenie do testowania aplikacji w środowisku Java

W tym poście powiemy sobie o jednym z najważniejszych aspektów tworzenia oprogramowania, mianowicie jego testowanie.
W środowisku programistów często powtarzane jest powiedzenie, że programowanie to tak naprawdę szukanie błędów i ich poprawianie. Christopher Thompson powiedział kiedyś: “Czasami bardziej opłaca się zostać w łóżku w poniedziałek niż spędzić resztę tygodnia, debugując poniedziałkowy kod”.
Każdy kto zetknął się z błędem używanego przez siebie oprogramowania, dobrze wie, jak frustrujące może to być dla użytkownika. Niestety są rzeczy gorsze, niż niezadowolony klient, błędy w oprogramowaniu mogą nieść ze sobą dużo bardziej druzgocące skutki. W skutek błędu w maszynie do radioterapii Therac-25, niektórzy pacjenci dostawali zbyt dużą dawkę promieniowania, przez co zmarło 5 osób. W 1966 roku, po 5 minutach lotu, awarii doznała sonda kosmiczna Mariner, błąd wynikał z nieprawidłowego przepisania wzoru z kartki i kosztował około 18,5 milionów dolarów. Przez błąd systemu obrony przeciwrakietowej PATRIOT w 1991 roku, nie udało się uniknąć ataku rakiety która zabiła 28 amerykańskich żołnierzy. Poprawka programu została wprowadzona następnego dnia… Zmiany w oprogramowaniu do projektowania CATIA i niezgodność wersji pomiędzy zespołami inżynierów pracujących nad projektem samolotu Airbus A380 spowodowały różnice w planach elektrycznych a tym samym niekompatybilność modułów, co spowodowało znaczne opóźnienie i dodatkowe koszta w wysokości ponad 6 miliardów dolarów. Błędy w oprogramowaniu przyczyniają się także do strat wynikających z użycia wirusów lub włamań komputerowych.
By uniknąć tych małych jak i tych większych błędów naszego oprogramowania coraz więcej w IT mówi się o testowaniu aplikacji. Jest to zagadnienie bardzo szerokie, zaś takie testy mogą odbywać się na wielu płaszczyznach, dlatego my tylko skupimy się na testach wykonywanych przez inżynierów oprogramowania.
Testowanie nie tylko zwiększa jakość i niezawodność naszego oprogramowania. Potrafi też znacząco ułatwić nam pracę. Początkowo, może się wydawać, że to strata czasu. Nasz projekt jest mały, mamy zapał do tworzenia nowego kodu a sprawdzenie czy wszystko działa zajmuje chwilę. Jednak z biegiem czasu, linijka za linijką, nasz kod jest coraz większy a program obsługuje coraz więcej funkcjonalności. Nagle przetestowanie wszystkiego by mieć pewność, że nasza mała zmiana nigdzie niczego nie popsuła potrafi zająć bardzo długi czas, a my mamy już dość robienia tego samego kolejny raz przez co przykładamy do tego mniej uwagi. W rezultacie boimy się wprowadzać większe zmiany, bo przecież “tamto działało” i chcemy ten stan zachować, zaś nasze testy są na tyle skąpe, że istnieje spora szansa, że i tak wszystkiego nie sprawdziliśmy. Tutaj z pomocą przychodzą nam właśnie testy. Stare powodzenie mądrego programisty mówi, jeśli robisz coś drugi raz ręcznie, zautomatyzuj to. Testy to nasz automat na usługach, który potrafi sprawdzić nam działanie naszego kodu i całej aplikacji w trakcie gdy my udamy się na krótką przerwę. Nie boimy się wprowadzać nawet największych zmian w naszym kodzie (np. tak zwanej refaktoryzacji), bo wiemy, że jeśli coś “popsujemy” to testy już o to zadbają, byśmy o tym wiedzieli. Takie testy także są dużo krótsze niż testowanie ręczne, samodzielne lub przez testerów, dlatego zachęcają do ich częstego używania, bez potrzeby uruchamiania naszej aplikacji. Dlatego okazuje się, że czas poświęcony na pisanie testów, w dłuższym rozrachunku do nas wraca! My za to śpimy spokojnie.
Kolejną bardzo dużą zaletą pisania testów do swojego kodu, jest swoistego rodzaju dokumentacja naszego kodu. Patrząc na testy w naszym kodzie, widząc co one sprawdzają, jaka funkcjonalność jest testowana, możemy bardzo szybko poznać co ten program robi, bez potrzeby analizowania samego kodu, linijka po linijce. Jest to bardzo przydatne czytając czyjś kod. Pracując w dużym zespole zawsze będziemy czytać i przeglądać kod naszych kolegów, testy jednocześnie ułatwiają nam to, z drugiej strony pilnują czy nasze zmiany nie spowodują problemów z czyimś kodem. Tą relację można odwrócić, czyli pisać testy zgodnie z naszymi wymaganiami do systemu czy przypadkami użycia.
Bywają też takie przypadki, że trafiamy do projektu który jest już prowadzony od dłuższego czasu, mającego wiele linii, mnóstwo funkcjonalności, brakuje dokumentacji a my nawet nie mamy się kogo spytać co się tam dzieje. Często taka aplikacja zależy od niewspieranego już systemu, języka, frameworku czy innych narzędzi. Mówimy wtedy o tak zwanym “Legacy Code” (polskie tłumaczenie “Odziedziczony kod”). Niestety takie systemy także nie mają zwykle testów, przez co praca z takim kodem przypomina trochę chodzenie po polu minowym. Michael Feathers, autor bardzo popularnej książki “Working Effectively with Legacy Code”, nazywa wręcz systemy “legacy” właśnie takimi które nie mają testów, mają ich bardzo mało lub same testy są nieprawidłowe. Wtedy jedną z zalecanych metod pracy w takim systemie jest właśnie rozpoczęcie pracy od napisania testów do niego i tym samym częściowo spłacenie tak zwanego “długu technologicznego”, czyli naprawienia niedociągnięć naszym poprzedników. Dobry zwyczaj skautów przecież nakazuje by pozostawiać swoje miejsce czystszym niż się je zastało!
Kolejną dużą zaletą testów, jest pomoc w dbaniu o nasz kod i ogólną architekturę aplikacji (często używane jest tutaj bardzo popularne w świecie IT, francuskie słowo “design”, jednak odnosi się znaczeniowo do aspektu wizualnego, np. dzieła sztuki, stąd nie będziemy go nadużywać, polskim odpowiednikiem jest słowo “wzornictwo” którego tutaj pewnie by nikt nie użył…). Okazuje się, że do złego kodu, gdzie panuje nieład i jest pisany niezgodnie ze sztuką, bardzo trudno napisać dobre testy. Bywają takie sytuacje, że to test powoduje, że programista upraszcza swój kod, by było go łatwiej przetestować a zyskuje na tym cały system.
Ostatnią zaletą i zastosowaniem naszych testów, jest możliwość wykorzystania ich do uczenia się nowych bibliotek, frameworków czy narzędzi. Po prostu piszemy testy do funkcjonalności których chcemy użyć. Z drugiej strony wiele narzędzi o otwartym kodzie jest pozbawionych dokumentacji, bądź jest bardzo uboga i wtedy przeglądając testy twórców tego narzędzia można naprawdę bardzo szybko się nauczyć wykorzystania tego narzędzia.
Podsumowując, piszemy testy by:
- tworzyć dobre przetestowane programy (minimalizujemy prawdopodobieństwo błędów działania)
- zapewnić lepszą architekturę (design) naszego systemu
- nie bać się zmian (refaktoryzacja kodu)
- nie psuć tego co było (regresja)
- szybka informacja że coś poszło nie tak
Należy także pamiętać, że nie zawsze testy spełniają nasze powyższe wymagania. Dzieje się tak głownie wtedy gdy testy są bardzo słabe, niezgodne ze sztuką którą za chwilę będę chciał Wam przybliżyć. Wtedy niestety testy nie testują zbytnio naszego kodu, sprawiają tylko takie pozory, utrudniają nam pracę nad nowościami bo nagle ich utrzymanie i zmienianie wraz z systemem wymaga większego czasu niż pisanie samego kodu i dochodzimy do wniosku, że testy są niepotrzebne, wyłączamy je i ich już nie używamy albo wręcz usuwamy. Dlatego tak bardzo ważne jest, by nauczyć się pisać dobre testy, by dawały nam korzyści a nie były kulą u nogi.
Rodzaje testów
W świecie IT spotykamy wiele różnych rodzajów testów. Wyróżniamy tutaj testy:
- Jednostkowe (tak zwane unit testy) - łatwe do tworzenia i modyfikacji, testują małą funkcjonalność, mały fragment kodu w oderwaniu od reszty systemu.
- Integracyjne (inaczej testy warstwy serwisów) - w tych testach skupiamy się na sprawdzeniu czy nasze moduły / komponenty / fragmenty kodu potrafią ze sobą współpracować, testujemy samą ich integrację, bez wnikania czy te moduły są prawidłowe, gdyż to robią testy jednostkowe.
- End-to-end (inaczej funkcjonalne lub akceptacyjne) - testy całościowe, sprawdzają jakąś funkcjonalność systemu w sposób całościowy, np. od wejścia do wyjścia gdy przetwarzamy jakieś dane, niekiedy też tutaj pojawiają się testy warstwy interfejsu dla użytkownika, czyli tak zwane testy UI (user interface), choć nie każdy system komputerowy taką warstwę w ogóle ma.
Zdarza się, że ludzie wprowadzają dodatkowe typy testów jak testy wydajnościowe czy testy penetracyjne (związane z bezpieczeństwem informatycznym), jednak trzy powyższe grupy są najbardziej uniwersalne, by nie rzecz najważniejsze, stąd skupimy się głownie na nich. Niekiedy też powyższe grupy są rozbijane na mniejsze.
Z racji tego, że testy jednostkowe są testy szybkie w działaniu, mają krótki kod i łatwo je tworzyć, znowu testy End-to-end są bardzo wolne, długotrwałe, trudne do napisania i utrzymania (edycji) stworzono coś takiego jak piramida testów.
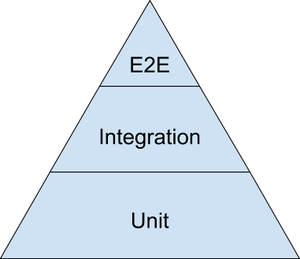
Piramida ta określa nam, które testy powinny być dominujące w naszym systemie a których powinno być najmniej. Oczywiście nie trudno się domyślić, że to małe i szybkie testy jednostkowe zajmują miejsce na spodzie naszej piramidy, czyli jest ich najwięcej, zaś testy całościowe są najrzadsze. Testy integracyjne są w centrum naszej piramidy. Często ludzie podają tutaj proporcje 70% - 20% - 10% ale w piramidzie nie chodzi o to by się sztywno trzymać tych proporcji, bo jeśli widzimy potrzebę napisania dodatkowego testu End-to-end to go napiszmy, nawet gdyby to miało oznaczać, że będzie ich 11% a nie 10%. Traktujmy piramidę jako wskazówkę, testuj co się da testami jednostkowymi, nigdy ich nie żałuj a integracyjnych i całościowych używaj tyle ile trzeba. Gdy proporcje piramidy są zaburzone, zastanów się czy testy integracyjne i End-to-end nie powinny być zastąpione jednostkowymi, bo testują tylko niewielką funkcjonalność systemu.
Kiedy pisać testy?
Większość programistów pisze swoje testy po napisaniu kodu, czyli najpierw mała funkcjonalność, potem test jednostkowy który ją sprawdza. Istnieje jednak inne podejście związane z pisaniem kodu, czyli Test Driven Developmnet. Technika zwana w skrócie TDD zakłada pisanie testów na samym początku a dopiero potem kodu który zapewni w systemie spełnienie tego testu. Takie odwrócenie ma wiele zalet w stosunku do “klasycznego” podejścia, czyli twórz a potem sprawdź czy działa. Przede wszystkim, zawsze napiszemy te testy, nie ma tutaj miejsca na lenistwo lub brak czasu bo przekroczyliśmy termin oddania nowej funkcjonalności systemu. Takie testy przed kodem wymuszają także lepsze odwzorowanie testów i wymagań systemu a co za tym idzie testy są lepszej jakości i uwzględniają większą ilość kodu systemu podczas testowania (tak zwane pokrycie kodu testami).
Technika ta została zaproponowana przez Kenta Becka i polega w dużym skrócie na tworzeniu oprogramowania w trzech powtarzających się fazach:
- Tworzymy testy do wymagań systemu (test oczywiście będzie nieudany na tym etapie)
- Piszemy kod danej funkcjonalności który ma zapewnić działanie testu
- Refaktoryzacja stworzonego kodu, tak by podnieść jego jakość i żeby spełniał standardy
Fani TDD potocznie te fazy nazywają Red, Green, Refaktor.
Jak to wygląda w praktyce?
Można by długo jeszcze opowiadać o testach czysto teoretycznie, ale czas na kilka przykładów. Wykorzystamy do tego najpopularniejszą bibliotekę testującą dla środowiska Java jaką jest JUnit. Dodatkowo skorzystamy z narzędzia Apache Maven którego poznaliśmy tydzień temu. Na pokład wyciągniemy także program kalkulatora z wyzwania numer trzy.
Wprowadziliśmy tam klasę Fraction która miała reprezentować ułamek czyli licznik i mianownik wraz z częścią całkowitą.
Zaczynamy więc od napisania powyższych wymagań, tworzymy pusty projekt zgodnie z postem dotyczącym Apache Maven i zaczynamy programować tworząc taką klasę:
package pl.kodolamacz.math;
public class Fraction {
private int fractionInteger;
private int numerator;
private int denominator;
}
Na razie idzie prosto. Jednak klasa jeszcze nic nie potrafi, pola są prywatne (hermetyzacja), więc tworząc taką klasę nie mamy nawet do nich dostępu… Dlatego stwórzmy sobie dodatkowo konstruktor tej klasy oraz funkcję która zwraca nam ułamek w postaci dziesiętnej, czyli po prostu typ double. Dostajemy zatem taki kod:
package pl.kodolamacz.math;
public class Fraction {
private int fractionInteger;
private int numerator;
private int denominator;
public Fraction(int fractionInteger, int numerator, int denominator) {
this.fractionInteger = fractionInteger;
this.numerator = numerator;
this.denominator = denominator;
}
public double getFractionAsDecimal() {
return fractionInteger + numerator / denominator;
}
}
Na pierwszy rzut oka wszystko wygląda prawidłowo, konstruktor przyjmuje wszystkie trzy parametry, zaś metoda konwertująca do double zwraca zarówno część całkowitą jak i ułamek właściwy. Spróbujmy zatem to sprawdzić!
Zaczynamy od dodania do Mavena odpowiedniej biblioteki. Nasz plik pom.xml powinien wyglądać tak:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>pl.kodolamacz</groupId>
<artifactId>java-challenges</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.2.0</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>10</source>
<target>10</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Słowo scope w Mavenie ustawione na test oznacza, że ta biblioteka będzie używana tylko do testów ale nie trafi dla przykładu do stworzonych plików jar.
Dzięki JUnit możemy dodać swój pierwszy test w nowej klasie FractionTest:
package pl.kodolamacz.math;
import static org.junit.jupiter.api.Assertions.*;
class FractionTest {
}
Klasy tej jednak nie tworzymy w ścieżce “scr/main/java” tylko w “src/test/java”.
Jednak to dopiero początek, potrzebujemy metody która będzie testować naszą klasę Fraction:
package pl.kodolamacz.math;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class FractionTest {
@Test
public void shouldGetFractionAsDouble(){
// given
// when
// then
}
}
Jak widać metoda swoją nazwą wprost pokazuje co tak naprawdę testuje, a właściwie czego wymaga od naszej klasy Fraction czyli “powinna zwrócić ułamek jako typ double”. Dodatkowo metoda ta została oznaczona adnotacją @Test wskazującą, że jest to metoda testowa i ma być specjalnie potraktowana przez framework testowy, czyli JUnit. Takich adnotacji jest kilkanaście i są one opisane na w dokumentacji projektu. Dzięki nim możemy na przykład sparametryzować testy, wykonywać jakieś akcje przed i po każdej metodzie testowej lub zbiorczo przed i po wszystkich metodach testowych w klasie testowej.
Dodatkowo test został podzielony na trzy logiczne części:
- given - przygotowujemy dane testowe
- when - wykonujemy test
- then - sprawdzamy czy rezultat jest taki jak oczekiwany
Nie jest to wymóg by tak pisać testy, jednak jest to dobry zwyczaj który polecam.
Nasz test jednak jeszcze niczego nie robi, czas uzupełnić powyższe fazy:
package pl.kodolamacz.math;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class FractionTest {
@Test
public void shouldGetFractionAsDouble() {
// given
Fraction fraction = new Fraction(1, 1, 2);
// when
double fractionAsDecimal = fraction.getFractionAsDecimal();
// then
assertEquals(1.5, fractionAsDecimal);
}
}
W powyższym kodzie w fazie given stworzyliśmy obiekt typu Fraction, czyli nasz ułamek, w fazie when zwróciliśmy wartość double która ma ge reprezentować, zaś na koniec w fazie then sprawdzamy czy 1 i 1/2 to faktycznie 1,5.
Do sprawdzania używamy tak zwanych asercji czyli specjalnych metod z frameworku JUnit lub dodatkowej biblioteki, które pozwalają nam porównać wartość zwróconą z wartością oczekiwaną.
Uruchamiamy test (w idei np. klikając go prawym przyciskiem myszy i wybierając opcję Run) i ku naszemu zdziwieniu dostajemy błąd:
org.opentest4j.AssertionFailedError:
Expected :1.5
Actual :1.0
<Click to see difference>
at org.junit.jupiter.api.AssertionUtils.fail(AssertionUtils.java:56)
at org.junit.jupiter.api.AssertEquals.failNotEqual(AssertEquals.java:197)
at org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:74)
at org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:69)
at org.junit.jupiter.api.Assertions.assertEquals(Assertions.java:443)
at pl.kodolamacz.math.FractionTest.shouldGetFractionAsDouble(FractionTest.java:18)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
Wygląda na to, że metoda która zwraca double ma błąd, tak zwany bug. Dzieje się tak dlatego, że dzieląc licznik przez mianownik oraz sumując go z częścią całkowitą pracujemy na liczbach typu int, czyli całkowitych, a dopiero potem wynik konwertujemy do typu double. Niestety przez to nasz wynik traci częścią niecałkowitą podczas operowania na liczbach całkowitych, stąd zamiast 1,5 dostajemy tylko wartość 1.
Należy zatem w klasie Fraction napisać tak:
package pl.kodolamacz.math;
public class Fraction {
private int fractionInteger;
private int numerator;
private int denominator;
public Fraction(int fractionInteger, int numerator, int denominator) {
this.fractionInteger = fractionInteger;
this.numerator = numerator;
this.denominator = denominator;
}
public double getFractionAsDecimal() {
return fractionInteger + (double) numerator / denominator;
}
}
Gdy uruchomimy nasz test ponownie, dostajemy “zielony” wynik, czyli wszystko jest jak należy!
Narzędzia do testowania aplikacji napisanych w języku Java
JUnit nie jest jednym narzędziem używanym do testowania aplikacji, jest ich właściwie coraz więcej. Polecam przyjrzeć się takim projektom jak:
- TestNG
- Mockito
- PowerMock
- AssertJ
- Hamcrest
- Arquillian
- Spock
- JWalk
- Grinder
- JMeter
- PIT
- Cucumber
- JBehave
- Selenium
Do sprawdzania pokrycia kodu testami możemy użyć:
To nie są jedyne narzędzia wspomagające testowanie aplikacji w języku Java, jednak z całą pewnością jedna z najpopularniejszych i warto się przyjrzeć tym projektom.
Zakończenie
W tym poście chciałem Was zachęcić do testowania swojego kodu. Pokazałem zalety takiego testowania oraz podstawy ich tworzenia w środowisku Java. Niestety temat testowania aplikacji jest bardzo szeroki i długo można by było o nim mówić, dlatego już we własnym zakresie polecam dalsze zgłębianie tej wiedzy.
Jeżeli jeszcze tego nie zrobiliście, koniecznie dołączcie do naszego programistycznego wyzwania na Facebooku, nadróbcie zaległe wyzwania i kontynuujcie wspólnie z nami przygodę z Javą.



